
Once again, it was my distinct privilege to be a BSidesSF CTF organizer! As somebody who played CTFs for years, it really means a lot to me to organize one, and watch folks struggle through our challenges. And more importantly, each person that comes up to us and either thanks us or tells us they learned something is a huge bonus!
But this week, I want to post writeups for some of the challenges I wrote. I’m starting with my favourite - Gman! Gman is a clone of Pacman. I tried hard to make it pretty, though it doesn’t seem like it looks great in most terminals, which is kind of sad. But here’s what it’s supposed to look like:
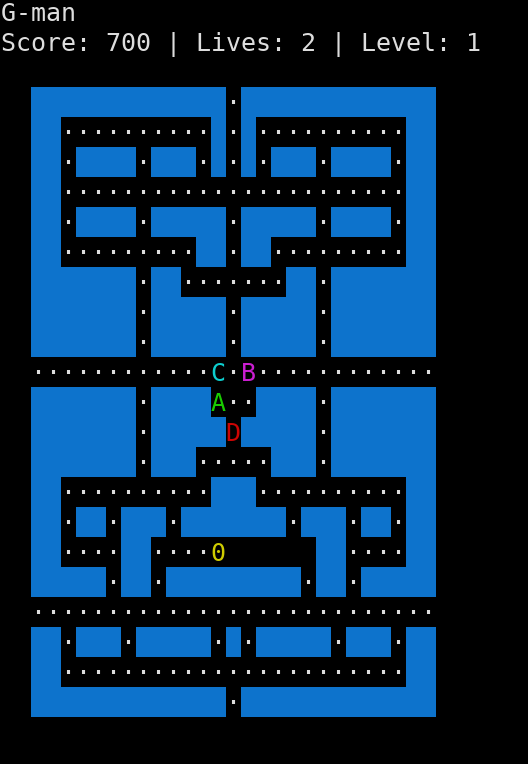
The trick to solving it was two-fold:
- There is a password screen that lets you skip levels
- Level 101 is a "kill screen" - it lets you play the game in stack memory
The password
This is what the password entry looks like:
A B C D E F G
┌───┬───┬───┬───┬───┬───┬───┐
1 │ │ │ ◆ │ ◆ │ │ │ │
├───┼───┼───┼───┼───┼───┼───┤
2 │ ◆ │ │ ◆ │ │ ◆ │ │ │
├───┼───┼───┼───┼───┼───┼───┤
3 │ ◆ │ ◆ │ ◆ │ │ │ │ │
├───┼───┼───┼───┼───┼───┼───┤
4 │ ◆ │ │ │ │ │ │ ◆ │
├───┼───┼───┼───┼───┼───┼───┤
5 │ │ │ │ │ ◆ │ ◆ │ ◆ │
├───┼───┼───┼───┼───┼───┼───┤
6 │ │ │ ◆ │ │ ◆ │ │ ◆ │
├───┼───┼───┼───┼───┼───┼───┤
7 │ │ │ │ ◆ │ ◆ │ │ │
└───┴───┴───┴───┴───┴───┴───┘
Toggle with <space>
Submit with <enter>
The password is actually three 8-bit values - level, lives, and random seed. It’s stored in a grid of 49 bits. The grid is rotationally symmetric - that means each bit in the data is represented by two bits in the grid, for a total of 48 bits. Notice that if you take the top-left triangle and rotate it 180 degrees around its center, you get the bottom-right half.
The final bit - the single bit center of the grid - is a parity bit. It’s set to 1 for an even number of bits, and 0 for an odd number.
You can find the full code here, but here is the important part (with formatting code stripped out):
// We can store 24 bits of data
void print_password(uint8_t a, uint8_t b, uint8_t c) {
// Pack into a uint32
uint32_t passcode = (a << 16 | b << 8 | c);
// Xor it to make it more random looking
passcode = passcode ^ 0x555555;
// Set each bit appropriately
int i;
// Setting the checksum to 1 means that all-blank won't be valid
int checksum = 1;
int bit = 23;
for(i = 0; i < 7; i++) {
int j;
for(j = 0; j < (i > 2 ? (6 - i) : (7 - i)); j++) {
uint8_t thischar = (passcode >> bit) & 0x01 ? 1 : 0;
bit--;
// Count the number of bits
checksum ^= thischar;
print_to_grid(j, i, thischar ? ACS_DIAMOND : ' ');
print_to_grid(6-j, 6-i, thischar ? ACS_DIAMOND : ' ');
}
}
// Print the checksum
print_to_grid(3, 3, checksum ? ACS_DIAMOND : ' ');
}
Note that it prints a triangle - the first row, it prints 7 characters; the second, it prints 6, and so on. Meanwhile, it prints the same to the other half of the grid.
The only value that ultimately matters is the level. I wanted to use the full 24 bits, so I stored the number of lives (for verisimilitude - that’s what a game would do, right?) as well as the random seed (I kept getting killed by my own AI! thought it’d be helpful).
The code above works out to level 101, and there are 100 initialized levels. The trick of the password is getting to level 101, which the code above will do for you.
Eating up the stack
If you go to level 101, it’s going to look a bit different depending on your operating system, libraries, etc. But this is what it looks like on mine:
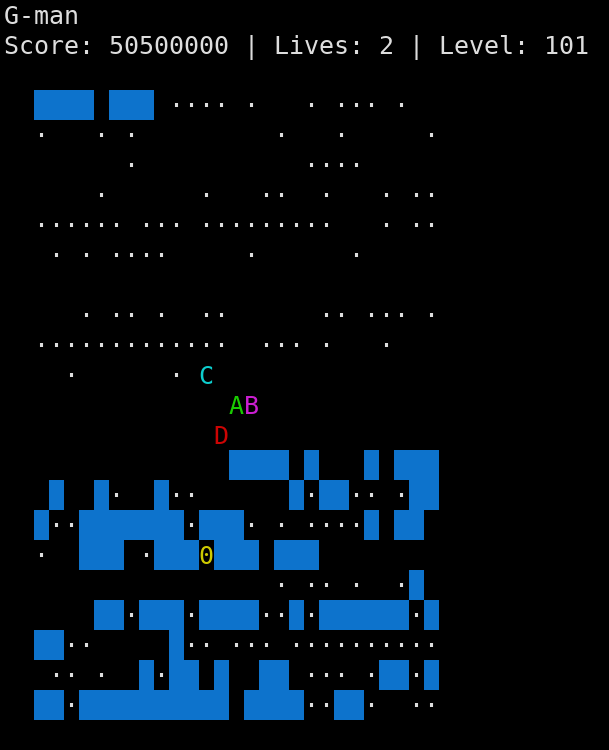
The two important values are at the start of instructions():
char name[256];
void instructions() {
char *highscore_file = "/home/ctf/highscores.txt";
The name variable is user-controlled, and the highscore_file variable is read and displayed at the end. I spent a lot of time with a totally working game before deciding what the exploitation path was - hence adding highscores.
Coincidentally (but not really, because I tried really hard to make it work like this), you can unset bits from highscore_file to point it instead at the name pointer:
FILE: 0x0804d1f9 => 11111001110100010000010000001000
NAME: 0x08041140 => 01000000000100010000010000001000
Unset => ^ ^^^ ^^^
On the actual game board, that looks like:

If you eat those bits, then either die or press ‘q’, you’ll get the flag instead of the highscores:
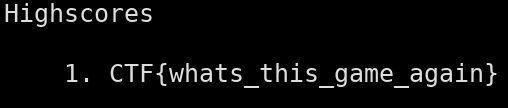
And that’s it!
An emergent bug
One small bug that was unintentionally but turned out be really helpful: the “ghosts” can’t turn 180 degrees, which means if a ghost ends up wandering into a square with only one way out, it gets stuck - ghost D and B are stuck in the same square here:
Originally it caused an infinite loop looking for a direction to go. I actually found it really helpful while testing to get all the ghosts stuck, so I decided not to fix it completely - now if they get stuck, they just give up and you can roam freely!
Comments
Join the conversation on this Mastodon post (replies will appear below)!
Loading comments...